
Miten ratkaista palapeli, jossa on 1,56 miljardia palaa
– tai haastava reitti gigaskaalan datasetteihin koneoppimisen kiihdyttämää virtuaaliseulontaa varten
Lääkeaineiden etsimisessä käytetään tyypillisesti nopeita laskennallisia seulontamenetelmiä, joiden avulla pyritään löytämään pieniä orgaanisia molekyylejä, jotka sitoutuvat tarkoitettuun kohteeseen, esimerkiksi patogeenin selviytymisen kannalta kriittiseen entsyymiin. Kohde voidaan kuvitella osittain valmiiksi biologiseksi 3D-palapeliksi.
Tässä analogiassa laskennallinen telakointi edustaa menetelmää, joka yrittää sovittaa jokaisen palan satojen ehdokkaiden joukosta olemassa olevaan palapeliin. Se, miten hyvin muoto ja kuvio sopivat yhteen, muunnetaan ”telakointipistemääräksi”, jonka avulla telakointi ennustaa sopivuutta.
Biologisen palapelin juju? Täydellistä yhteensopivuutta ei ole! Siksi lääketutkimushankkeissa käytetään tyypillisesti tuhansia erilaisia pieniä molekyylejä, jotta löydettäisiin ne muutamat, jotka sopivat mahdollisimman hyvin haluttuun kokonaiskuvaan ja saavat siten parhaat pisteet.
Pistemäärän ennustaminen koneoppimisen avulla
Käytettävissä olevien molekyylikirjastojen koko on viime aikoina vaarantanut tämän raakaan laskentavoimaan perustuvan telakointitavan (brute force). Nykyaikaisten molekyylikirjastojen koko ylittää miljardiluokan. Kokonaisen kirjaston telakointi vaatisi kuukausia tai vuosia, vaikka käytössä olisivat supertietokoneet.
Entä jos olisi olemassa nopeampi tapa ennustaa kappaleen sopivuus? Tässä koneoppiminen on avuksi: kun sille esitetään riittävästi esimerkkejä ja niitä vastaavat pisteet, se voi oppia, miksi jotkin kappaleet sopivat hyvin ja toiset huonosti. Telakointipisteytyksen ennustaminen tällaisen mallin avulla on tällöin paljon nopeampaa kuin perinteiset telakointimenetelmät.
Ei ole yllättävää, että koneoppimisella kiihdytetystä telakoinnista nykyaikaisten gigaluokan molekyylikirjastojen aikana on tullut suosittu lähestymistapa – mutta siinä on yksi haaste: Ennuste on tuskin koskaan täydellinen, ja näin ollen osa parhaista paloista saattaa jäädä saamatta. Jos kehittäisit uudenlaisen menetelmän telakoinnin nopeuttamiseksi, menetelmäsi käyttäjät haluaisivat todennäköisesti tietää, kuinka monta – ja niin halusimme mekin.
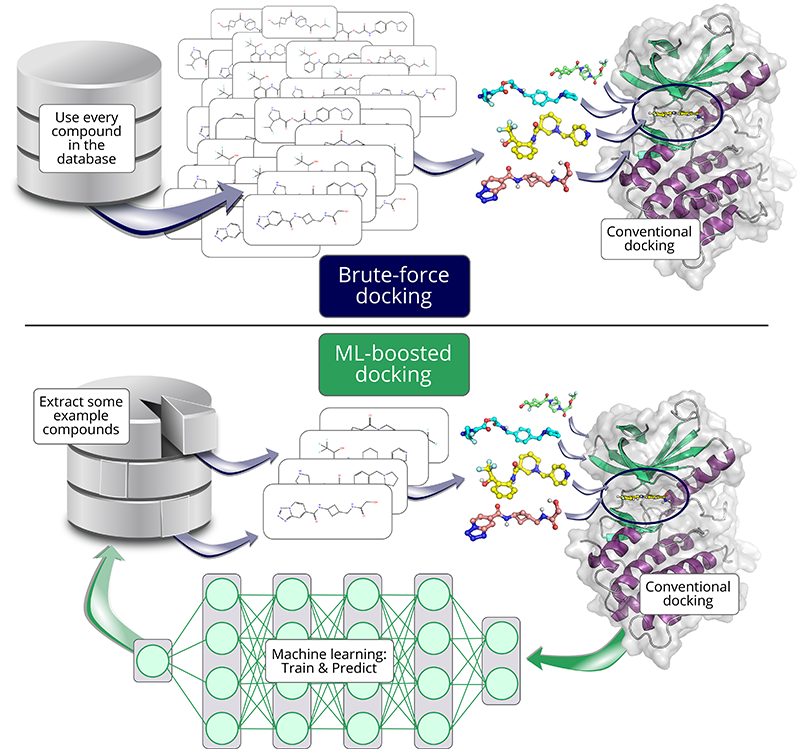
Yksi työkalu, jolla voidaan nopeuttaa telakointitutkimuksia koneoppimisen avulla, on HASTEN. HASTENin on aiemmin osoitettu onnistuneesti nopeuttavan miljoonien yhdisteiden telakointia, mutta miten työkalu pärjäisi gigaskaalassa?
On tuskin yllättävää, että useimpia työkaluja ei ole tosiasiassa vertailtu gigaskaalan datalla. HASTENiakaan ei oltu testattu ennen meidän tutkimustamme. Koneoppimisen lähestymistapojen vertaaminen raa’an voiman telakoinnin tuloksiin edellyttää ensin perustiedon saatavuutta: Kaikkien miljardien molekyylien kaikki pisteet on tunnettava, jotta voidaan määrittää, mitä molekyylejä koneoppimismalli ei löydä.
Neljästä kuukaudesta 10 päivään
Määrittääksemme tarkasti, kuinka monta lupaavaa yhdistettä meiltä jäisi huomaamatta ja kuinka paljon aikaa voisimme säästää, lähdimme laskemaan 1,56 miljardin yhdisteen raa’an voiman telakointituloksia antibakteerista ja antiviraalista kohdetta vastaan – ja vertasimme niitä tuloksiin, jotka saatiin koneoppimisella kiihdytetyn HASTENin avulla.
Vaikka käytimme erityisen nopeaa Schrödinger Glide HTVS -menetelmää, telakointitutkimus olisi kestänyt silti useita kuukausia. Glide, kuten useimmat muutkin telakointityökalut, on kehitetty perinteisempiä kirjastokokoja silmällä pitäen. Tässä ennennäkemättömässä mittakaavassa kohtasimme useita käytännön haasteita, kuten tehtävän jakamisen tuhansiksi töiksi, jotta se mahtuisi CSC:n eräajorajoituksiin, ja samalla projektin edistymisen seurannan ja resurssien hallinnan. Kuvittele, että pöytäsi on tarkoitettu 1 000 palan palapelille, ja yhtäkkiä yritätkin saada siihen mahtumaan 1 000 000 000 palaa…
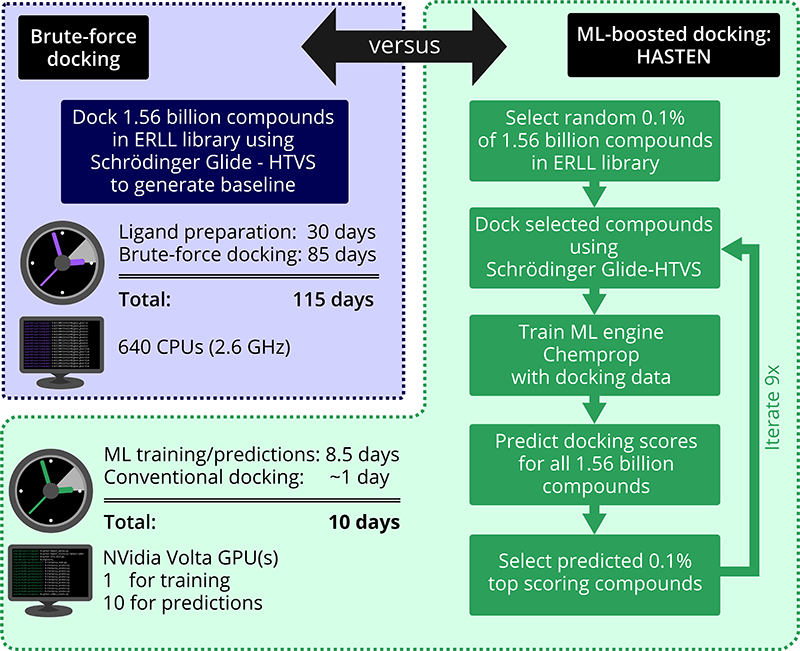
Hankkeessamme pystyimme osoittamaan, että HASTENin kaltaiset työkalut voivat lyhentää yli miljardin yhdisteen seulonta-aikaa neljästä kuukaudesta noin 10 päivään. Eikä vain sitä: Käyttämällä koneoppimisella tehostettua lähestymistapaa löysimme murto-osassa ajasta yli 90 prosenttia parhaimmiksi arvioiduista yhdisteistä eli referenssiaineistosta, joka oli laadittu raa’an voiman telakointimenetelmän avulla.
Kokonaisresurssien määrä ja niiden käyttöön liittyvät haasteet, joita kohtasimme tässä hankkeessa laskiessamme koulutus- ja vertailuaineistoa HASTENia varten, ovat keskeinen syy siihen, miksi monia vastaavia työkaluja ja lähestymistapoja ei ole validoitu tai testattu gigaskaalassa. Koska entistä suorituskykyisemmät menetelmät ovat ratkaisevan tärkeitä miljardien yhdisteiden kirjastojen tulevan käytön kannalta ja koska kirjastot kasvavat jatkuvasti, uusia menetelmiä kehitetään ja ne tarvitsevat asianmukaista vertailuanalyysia aiotussa käyttöskaalassa. Tätä varten julkaisimme koko 1,56 miljardin yhdisteen telakointituloksemme kahdelle kohteelle vertailutietona julkiseen käyttöön. Uskomme, että tällaisten datasettien saatavuus on ratkaisevan tärkeää koko alan kehityksen kannalta ja että se on pitkän aikavälin investointi huippuluokan seulontamenetelmiin, jotka säästävät kaikilta aikaa ja resursseja.
Lue lisää:
- Pre-print ChemRxiv: Machine Learning-Boosted Docking Enables the Efficient Structure-Based Virtual Screening of Giga-Scale Enumerated Chemical Libraries, Toni Sivula, Laxman Yetukuri, Tuomo Kalliokoski, Heikki Käsnänen, Antti Poso and Ina Pöhner. (https://doi.org/10.26434/chemrxiv-2023-g34tx)
Ina Pöhner
Kirjoittaja on tutkijatohtori Itä-Suomen yliopiston Molekyylimallinnuksen ja lääkeainesuunnittelun tutkimusryhmässä. Hän rakastaa dataintensiivisiä haasteita lääkeainesuunnittelussa ja ratkaisi tämän palapelin läheisessä yhteistyössä CSC:n asiantuntijoiden kanssa.
CSC:n rooli tehoseulonnan työvuon käyttöönotossa
CSC teki tiivistä yhteistyötä Itä-Suomen yliopiston kanssa, jotta virtuaalisen tehoseulonnan työvuon tehokas käyttöönotto onnistui Schrödingerin Maestro-ohjelmiston avulla.
Schrödingerin sisäänrakennettu työvuon automatisointi on suunniteltu pienemmille datamäärille, ja sen laajentaminen vaati yksityiskohtaista analyysia työn yksittäisistä vaiheista ja niiden kokonaisvaikutuksesta laskentajärjestelmään. Pelkkä skaalaus olisi ollut tehotonta ja se olisi häirinnyt muita käyttäjiä. Tässä vaiheessa päätimme myös siirtyä käyttämään Mahti-supertietokonetta saadaksemme käyttöön isommat resurssit, mikä edellytti myös erilaista toteutusta töiden käynnistämiseen.
Työvuon optimointiin kuului datasetin osittamisen suunnittelu huomioiden myös datan myöhempi käyttö ja julkaiseminen, tarpeettomien vaiheiden karsiminen, sisäänrakennettujen parametrien viilaaminen, rinnakkaistamisen optimointi, optimaalisen lisenssin käytön suunnittelu ja kaiken tämän kääriminen vikasietoiseen skriptiin.
Yksi kriittisistä muutoksista oli raskaiden levyn I/O-operaatioiden ohittaminen käyttämällä rinnakkaislevyjärjestelmän sijaan laskentasolmun muistia. Työnvuon nopeuttamisen lisäksi se minimoi häiriöt muille käyttäjille. Monet näistä vaiheista edellyttivät Mahdin infrastruktuurin syvällistä tuntemusta ja pääsyä järjestelmän seurantatietoihin. CSC:n ylimääräinen työ perusteltiin resurssien tehokkaalla käytöllä: muiden tutkijoiden käytössä olevat resurssit kasvoivat ja samalla parantunut tietämyksemme työvoista koituu ajan kuluessa kaikkien tutkimusryhmien hyödyksi.
Atte Sillanpää ja Laxmana Yetukuri, CSC