
Tehokasta molekyylidynamiikkaa LUMI-supertietokoneella
LUMI-supertietokoneen pääasiallinen laskentateho juontuu koneen mittavasta GPU-osiosta, LUMI-G:stä, joka koostuu 10 240 AMD MI250X -grafiikkaprosessointiyksiköstä. Näiden uusimman sukupolven kiihdyttimien korkea suorituskyky on jo todistettu useassa käyttötapauksissa, kuten luonnollisen kielen käsittelyssä sekä avaruussääsimulaatioissa, mutta miltä suorituskyky näyttää molekyylidynamiikassa? Juonipaljastus: erinomaiselta!
Klassinen molekyylidynamiikka (MD) mahdollistaa biomolekulaaristen järjestelmien, kuten proteiinien, atomimittakaavaisen simuloinnin ja on yksi käytetyimmistä menetelmistä CSC:n laskentaympäristössä.
Suosittu MD-sovellus on avoimen lähdekoodin GROMACS-ohjelmistopaketti, joka tunnetaan erityisesti sen tehokkuudesta ja monipuolisuudesta. Vaikka GROMACSilla on ollut erinomainen tuki Nvidia-grafiikkasuorittimille CUDA-ohjelmointimallin kautta pitkään, tuki AMD:n GPUille on kypsynyt vasta äskettäin OpenSYCL-sovelluskehyksen (aiemmin hipSYCL) kehityksen seurauksena, jota GROMACS käyttää GPU-kiihdytyksen mahdollistamiseen AMD-laitteistolla.
Kokemuksemme GROMACSista LUMI-G:ssä osoittavat, että useista sadoista tuhansista ja miljoonista atomeista koostuvat suuret järjestelmät pystyvät skaalautumaan erittäin hyvin kokonaisiin LUMI-G-solmuihin. Alla olevassa kuvassa verrataan GROMACS 2023.1:n suorituskykyä LUMI-G:ssä kansallisen Mahti-supertietokoneen CPU-suorittimiin.
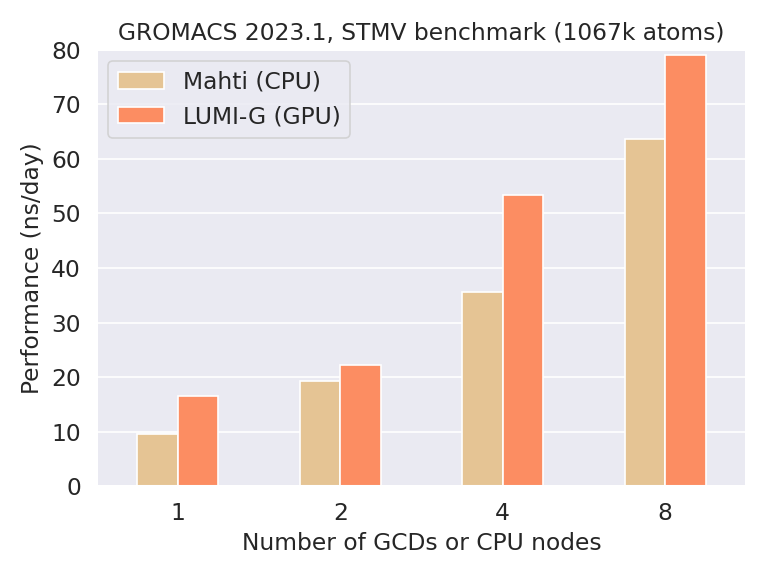
Tutkittu vertailujärjestelmä on eräs tupakan mosaiikkivirus (STMV), joka koostuu n. miljoonasta atomista. Hyvän skaalautumisen lisäksi yllä olevasta kuvasta näkyy, että jo yksittäinen AMD MI250X grafiikkalaskentasiru (GCD), joka vastaa puolta GPU:ta, ylittää tehokkuudessan yhden Mahdin CPU-solmun (128 ydintä). Tämä havainnollistaa hyvin LUMIn huippuluokan kiihdyttimien suorituskykyä, ja tätä tulisikin pitää viitteellisenä nyrkkisääntönä teho-odotuksista siirrettäessä simulaatioita LUMIin. Toisin sanoen, jos simulaatiosi on paljon hitaampi yhdellä MI250X GCD:llä verrattuna yhteen laskentasolmuun Mahdilla, on luultavasti eräajoskriptisi asetuksissa jotain, mitä voisi parantaa.
Yleinen syy alhaiseen suoritustehoon LUMI-G:ssä on se, että varattuja CPU-ytimiä ei ole sidottu oikeisiin GPU:ihin. LUMI-G:n solmuissa tietyt laskentaytimet on aina kytketty suoraan tiettyyn grafiikkasuorittimeen ja nopean kommunikaation varmistamiseksi tämä linkitys on syytä kertoa myös ajettavalle ohjelmalle. Varmistaaksesi asianmukaisen suorittimen ”sijoittelun”, katso eräajotemplaattimme Docs CSC:ssä!
Nopeus vs. suoritusteho
Edellinen vertailu osoittaa, että keskikokoiset ja varsinkin suuret käyttötapaukset soveltuvat hyvin ajettavaksi LUMI-G:llä. Mutta entä pienemmät, n. 10-100 tuhannen atomin, järjestelmät? Tällaisten simulaatioiden ajaminen yhdellä GCD:llä voi olla kohtuullisen tehokasta, mutta mitä pienemmäksi järjestelmä tulee, sitä huonommin se pystyy hyödyntämään kiihdyttimen koko kapasiteettia, skaalautumisesta puhumattakaan.
Onneksi LUMI-G:n MI250X-grafiikkasuorittimet tukevat useiden MPI-prosessien ajamista yhtä GPU:ta kohden Nvidian GPU:iden MPS-ominaisuuden tavoin. Toisin sanoen, jos pystyt jakamaan MD-käyttötapauksesi useisiin itsenäisiin simulaatioihin, usean pienemmän simulaation ajaminen kullakin GCD:llä nostaa merkittävästi GPU:iden käyttöastetta. Tyypillisiä esimerkkejä ovat sekä vapaaenergialaskut että rinnakkain ajettavat simulaatiopolut, joissa saman järjestelmän eri tavoin tasapainotettuja kopioita simuloidaan samanaikaisesti tilastollisen otannan kiihdyttämiseksi.
GROMACS:illa on mahdollista ajaa rinnakkaisia simulaatioita kätevästi sisäänrakennetun multidir-ominaisuuden kautta, joka jakaa allokoidut laskentaresurssit tasaisesti kaikkien järjestelmän kopioiden kesken. Käyttämällä kahta LUMI-G-solmua (16 GCD:tä), alla oleva vertailu osoittaa miten simulaatioiden määrän vaihtelu yhtä GCD:tä kohti vaikuttaa yhteenlaskettuun suorituskykyyn.
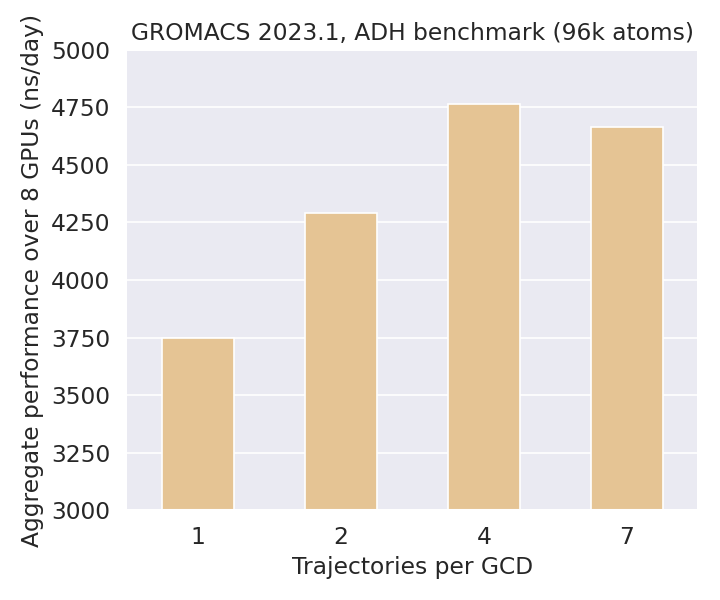
Tutkitun n. 96 000 atomin alkoholidehydrogenaasi (ADH) -entsyymin osalta simulaatioiden määrän lisääminen GCD:tä kohti yhdestä neljään parantaa kokonaissuorituskykyä noin yhdellä mikrosekunnilla/päivä paremman GPU-käytön ansiosta. Vaikka tätä kyseistä esimerkkiä ajettiin ainoastaan kahdella GPU-solmulla, voidaan käyttötapaus helposti skaalata mielivaltaiseen määrään solmuja, koska simulaatiot ovat täysin riippumattomia toisistaan.
Esimerkiksi kokonaissuorituskyky 100 mikrosekuntia/päivä voitaisiin saavuttaa käyttämällä 42 LUMI-G-solmua, mikä on alle 2 % GPU-osion kokonaiskapasiteetista. Samanlaisen suorituskyvyn saavuttaminen Mahdissa ajamalla yksi simulaatio 32 CPU-ydintä kohden vaatisi noin 560 solmun resurssiallokaation, joka vastaa 40 % koko Mahdista. Tämä on konkreettinen osoitus LUMI-supertietokoneen ennennäkemättömästä laskentakapasiteetista!
Pääviestit:
- Useimmat järjestelmät toimivat hyvin yhdellä GCD:llä, suorituskyky on yleensä parempi kuin yhdellä 128 ytimen CPU-solmulla
- Suuret järjestelmät (useita 100 000 – 1 M atomia) skaalautuvat todennäköisesti useisiin GPU:ihin (huomioi oikea linkitys suorittimien ja GPU:iden välillä)
- GPU-käyttöä voidaan tehostaa pienissä järjestelmissä (alle 100 000 atomia) jakamalla GPU:t useiden itsenäisten simulaatioiden kesken (multidir-toiminto)
- Älä epäröi ottaa yhteyttä CSC Service Deskiin (servicedesk@csc.fi), jos tarvitset apua simulaatioidesi siirtämisessä LUMIin!
Lue lisää:
- Luo LUMI-tili ja hae GPU-resursseja
- GROMACSin käyttö LUMI-G:ssä
- Korkean suoritustehon työvuot GROMACSilla
- LUMIn dokumentaatio
Rasmus Kronberg
Kirjoittaja työskentelee CSC:n tiedealatuessa laskennallisen kemian asiantuntijana.