
New fields of science go computational
CSC’s new supercomputers Mahti and Puhti and the data management system Allas increased the number of users of CSC services by more than 40%. During the procurement process, ministries dismantled their silos and in 2018 CSC services were also opened up to academic use by research institutes on the same terms as for university researchers. Between 2017 and 2021, the number of research institute users increased fivefold.
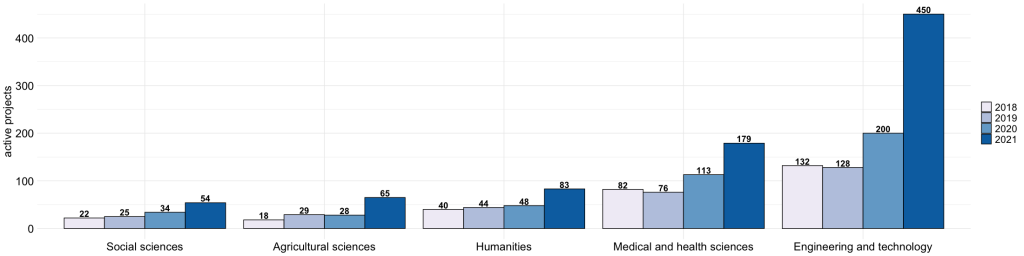
Throughout the supercomputing era, the natural sciences have been the largest branch of science in terms of users, projects and computing resources used. In the 1990s, we saw the rise of bioinformatics, and now the humanities, social sciences, agriculture, forestry, engineering, medicine and health sciences are new upstarts in the clientele of CSC computing services. In medicine science, the increasing use of image analysis is well reflected in the use of CSC resources. (Further information on the use of CSC resources)
In this blog, I present two examples of emerging computational research.
Multi-objective forests
Forests and their ability to capture and store carbon play an important role in achieving the Carbon Neutral Finland 2035 target. The important role of forests in climate change mitigation has been recognised.
In the joint project “FOSTER – Future multi-purpose forests and risks in a changing climate” by the Natural Resources Institute Finland, the Finnish Meteorological Institute and the University of Helsinki, the development of forests managed in different ways is being studied. The aim is to find out how and in what way forests should be managed, taking into account the different objectives set for forests and the risks posed by climate change.
“We will compare forest management with different ecosystem services such as wood production, recreational values provided by forests and forest biodiversity. In particular, we focus on how forests will evolve in a changing climate, taking into account different risks of forest damage,” says Juha Honkaniemi, project coordinator at the Natural Resources Institute Finland.
Ecosystem services refer to a variety of free tangible and intangible benefits provided by nature, such as food, raw materials, photosynthesis, water purification, climate regulation and recreation.
“We simulated forest development at the landscape level, in about 50 000 ha of forested areas, in southern and central Finland. In the simulated scenarios, for example, logging rates, the proportion of protected forest and rotation times for silviculture vary. This means that there are already dozens of different scenarios, and the stochasticity of the models and the size of the areas under consideration bring their own challenges to the computing. Among the CSC services, Puhti and Allas are currently in active use. In addition to simulations, we also use Puhti and the R interface for data analysis. For example, we have already computed models for deer habitat selection based on GPS data,” continues Juha Honkaniemi.
The project is one of the Hiilestä kiinni (Catch the carbon) projects funded by the Ministry of Agriculture and Forestry, which aim to explore themes relevant to Finland’s Carbon Neutrality 2035 goal.
Artificial intelligence identifies text types
Veronika Laippala, Professor of Digital Linguistics at the University of Turku, is modelling language use on the internet by combining linguistics, language technology and supercomputing.
“Our research focuses in particular on text genres; different types of texts found on the internet, such as user manuals, neutral news, columns containing the author’s opinions and interactive posts in discussion forums. Our aim is to understand the full range of these text types and to develop machine learning systems that can automatically recognise them,” says Veronika Laippala.
The results of the project will benefit all Internet users. Distinguishing between factual news and texts containing opinion is an essential part of media literacy and an important skill for everyone.
“The project has significant application value in the sciences, where large datasets automatically collected from the internet are used. For example, in the humanities, the internet provides vast amounts of data on human interactions and communications around the world, and in language technology, the data sets are being used to develop increasingly efficient systems for understanding and producing human language. All of these would benefit if, instead of a huge mass of raw data, the data collected from the Internet contained metadata about, for example, the types of text it contains. This would allow, for example, to control the type of language generated by language models (language technology systems that automatically produce human language) – news-language vernacular or colloquial slang,” Laippala continues.
The identification of text types is based on guided machine learning. Laippala’s research team uses texts in different languages as input, manually labelled with the text type they represent. Their methodology uses deep learning and language models pre-trained with large amounts of raw data, based on a transformer architecture.
“The resources provided by CSC play a primary role, as the methods require a lot of memory and computing power – in particular, we use the graphics processors of Puhti and Mahti,” says Laippala.
“In addition, we use the text recognition methods we have developed to analyse large data sets. These require not only processing power but also storage space. For example, the much-used Oscar dataset from the internet, to which we have added textual data, contains 351 million documents in 14 languages. CSC provides an excellent framework for all this – in fact, it gives us an edge over many of our international colleagues.”
Environment purchased under the DL2021 programme
CSC’s supercomputers Mahti and Puhti and data management system Allas were procured under the Ministry of Education and Culture’s Data Management and Computing Development Programme (DL2021). The supercomputer Puhti is meant for a wide range of use cases from data analysis to medium scale simulations. Puhti and its AI partition Puhti-AI were opened to researchers on 2 September 2019 and Allas one month later on 2 October 2019.
CSC’s national environment’s flagship, supercomputer Mahti is geared towards medium to large scale simulations. Mahti was generally available the following year on 26 August 2020. Mahti was extended with a graphics processing unit (GPU), Mahti-AI, which was introduced on 30 April 2021 to meet the ever-growing need for GPU computing.
For more information, see the Research Services Catalogue.
Tommi Kutilainen
The author has a few decades of experience in scicomm at CSC. Twitter: @TommiKutilainen